0x80072F17 Microsoft Store Error: How to Fix it
0x80080206 Microsoft Store Error: How to Fix it
0x8E5E0643 Microsoft Store Error: How to Fix It
What is WpSystem Folder & Should You Delete it?
0x80072f78 Error on Windows 10 & 11: How to Fix it
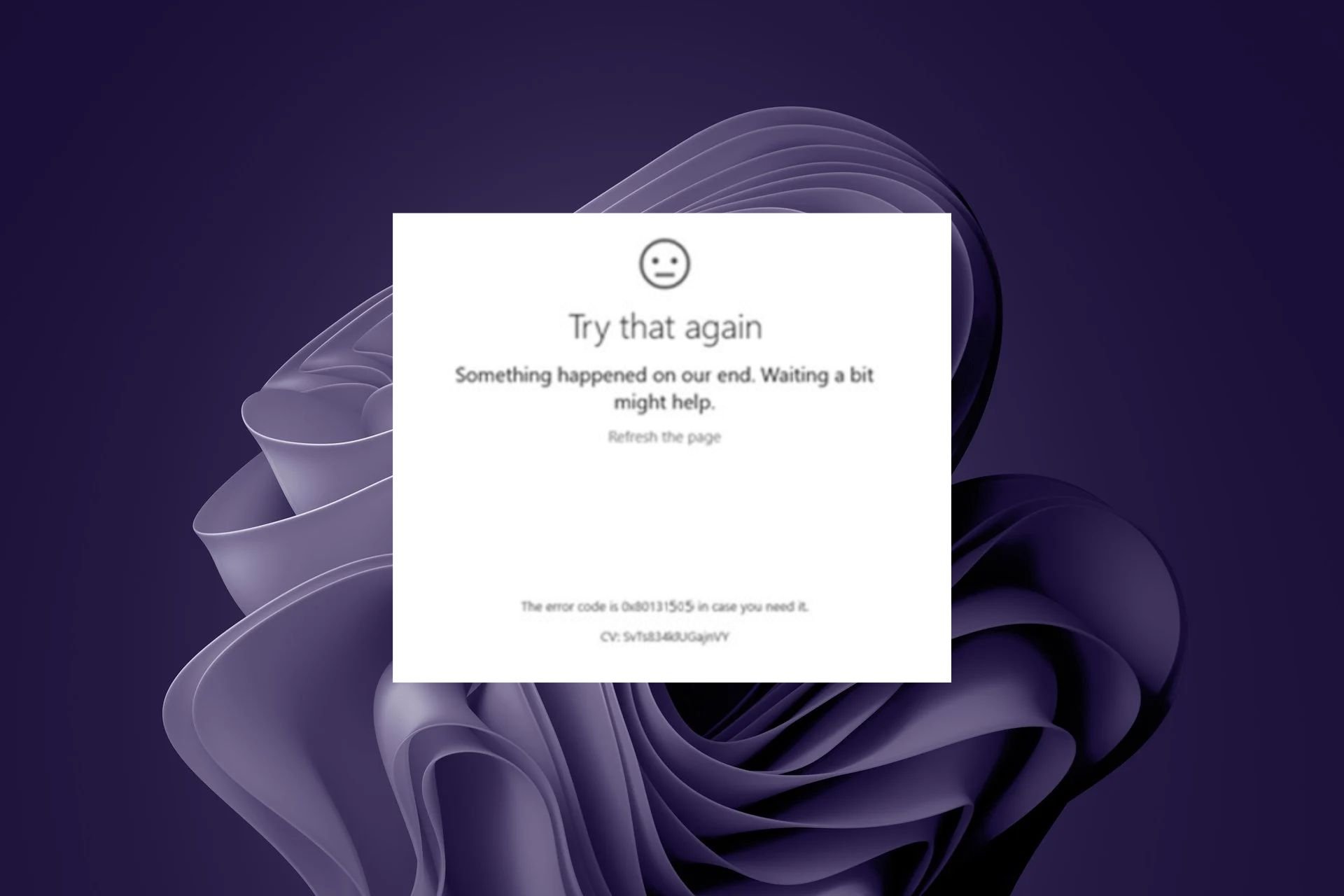
0x80131505 Microsoft Store Error: How to Fix It
0xc03F300D Microsoft Store Error: How to Fix It
Deployment Failed With HRESULT: 0x80073D06 [Fix]
No Applicable App Licenses Found: 5 Ways to Fix This Error
0x80073d23 Microsoft Store error: How to Fix it
0x80d03801 Microsoft Store Error: How to Fix It
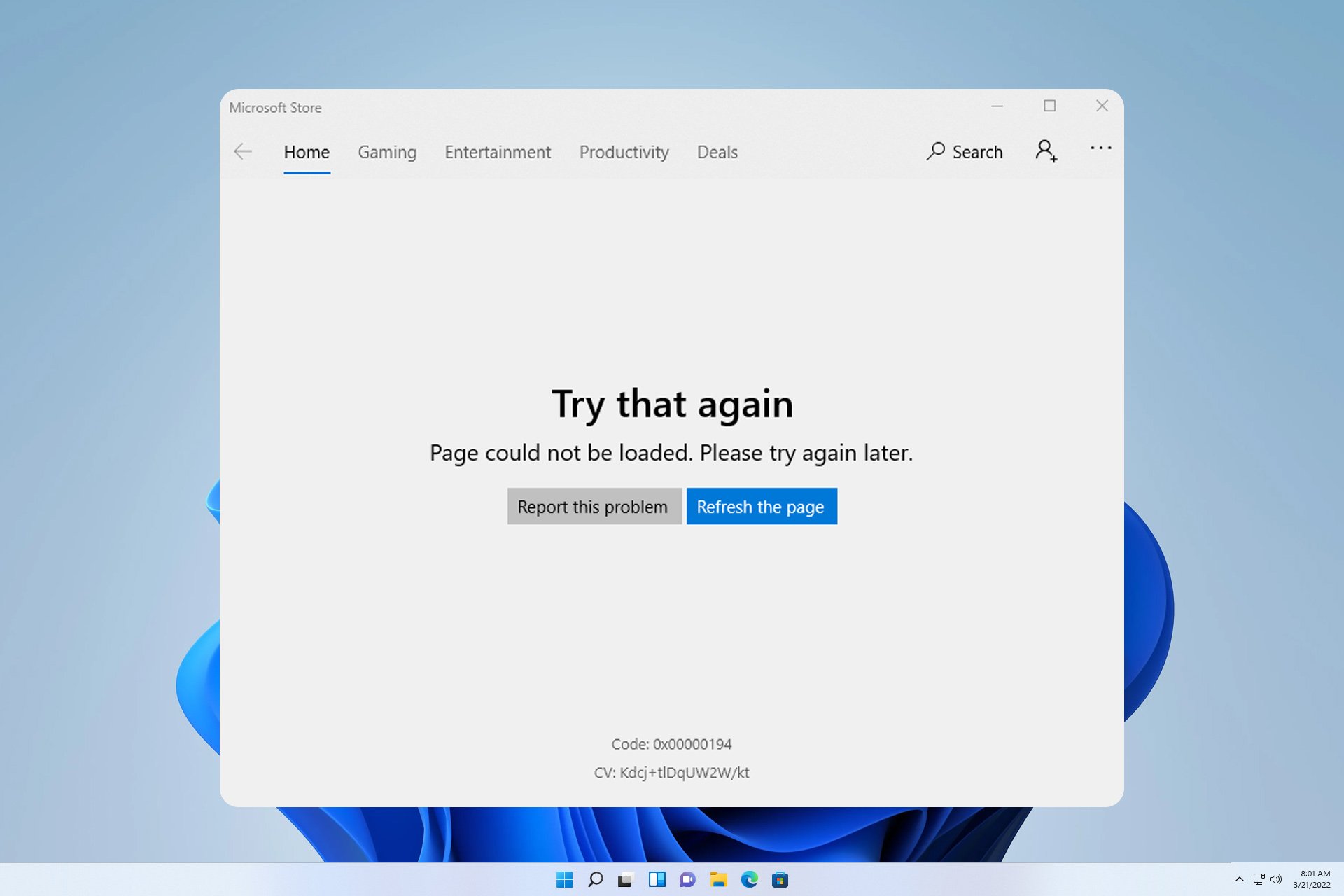
0x00000194 Microsoft Store Error: How to Fix It
Fix: 0xc000027b Microsoft Store Crash Exception Code
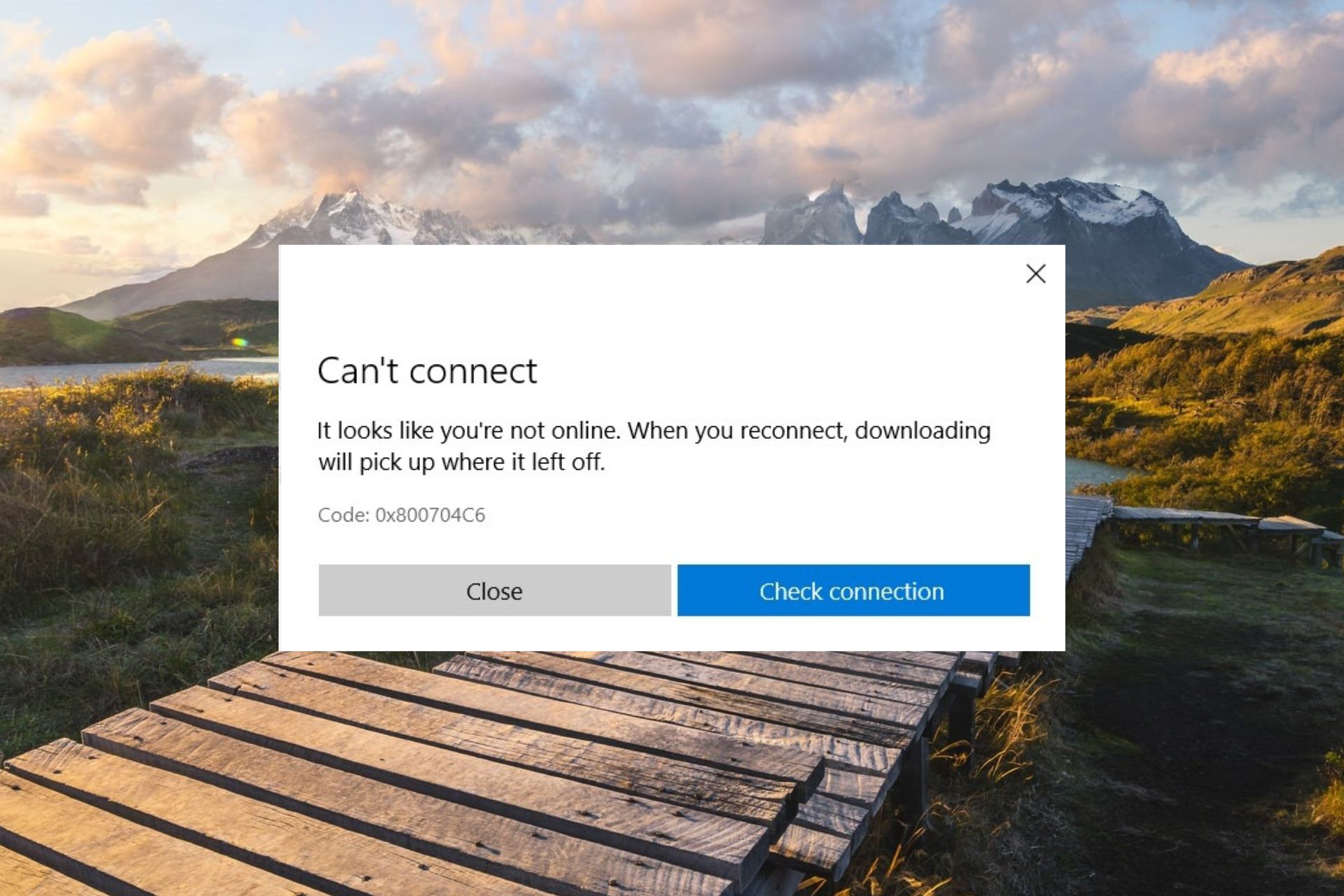
0x800704C6: How to Fix this Microsoft Store Error